
1. 호텔 데이터셋
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
hotel_df = pd.read_csv('/content/drive/MyDrive/KDT v2/머신러닝과 딥러닝/ data/hotel.csv')
hotel_df
pd.set_option('display.max_columns', 60)
hotel_df.head()
hotel_df.info()
0 hotel 119390 non-null object
1 is_canceled 119390 non-null int64
2 lead_time 119390 non-null int64
3 arrival_date_year 119390 non-null int64
4 arrival_date_month 119390 non-null object
5 arrival_date_week_number 119390 non-null int64
6 arrival_date_day_of_month 119390 non-null int64
7 stays_in_weekend_nights 119390 non-null int64
8 stays_in_week_nights 119390 non-null int64
9 adults 119390 non-null int64
10 children 119386 non-null float64
11 babies 119390 non-null int64
12 meal 119390 non-null object
13 country 118902 non-null object
14 distribution_channel 119390 non-null object
15 is_repeated_guest 119390 non-null int64
16 previous_cancellations 119390 non-null int64
17 previous_bookings_not_canceled 119390 non-null int64
18 reserved_room_type 119390 non-null object
19 assigned_room_type 119390 non-null object
20 booking_changes 119390 non-null int64
21 deposit_type 119390 non-null object
22 days_in_waiting_list 119390 non-null int64
23 customer_type 119390 non-null object
24 adr 119390 non-null float64
25 required_car_parking_spaces 119390 non-null int64
26 total_of_special_requests 119390 non-null int64
27 reservation_status_date 119390 non-null object
28 name 119390 non-null object
29 email 119390 non-null object
30 phone-number 119390 non-null object
31 credit_card 119390 non-null object
hotel_df.drop(['reservation_status_date', 'name', 'email', 'phone-number', 'credit_card'], axis=1, inplace=True)
hotel_df.describe()
sns.displot(hotel_df['lead_time'])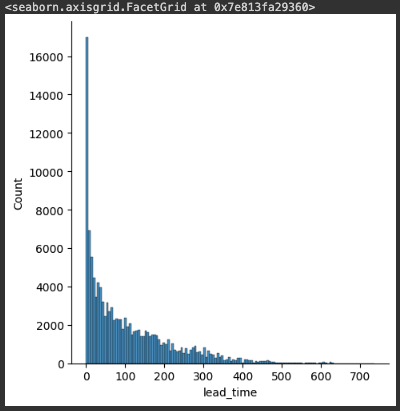
sns.boxplot(hotel_df['lead_time'])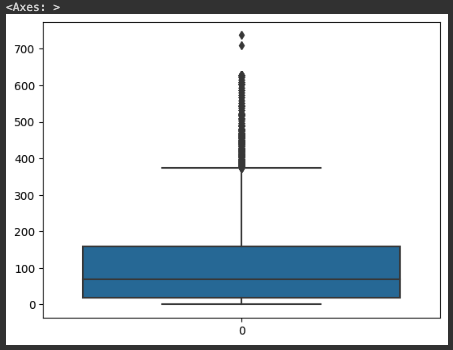
sns.barplot(x=hotel_df['distribution_channel'], y=hotel_df['is_canceled'])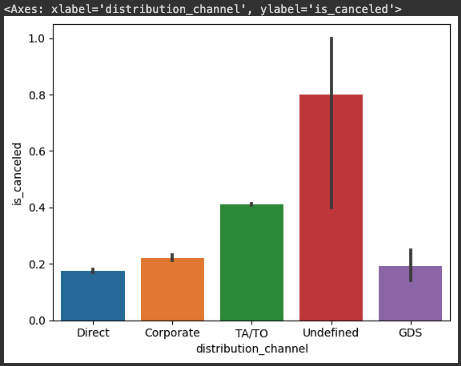
hotel_df['distribution_channel'].value_counts()
# 결과값 =>
# TA/TO 97870
# Direct 14645
# Corporate 6677
# GDS 193
# Undefined 5sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
sns.barplot(x=hotel_df['arrival_date_year'], y=hotel_df['is_canceled'])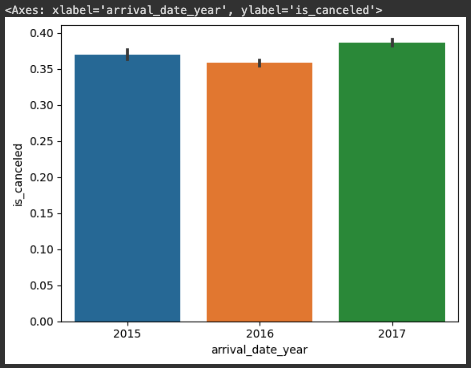
plt.figure(figsize=(15, 5))
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'])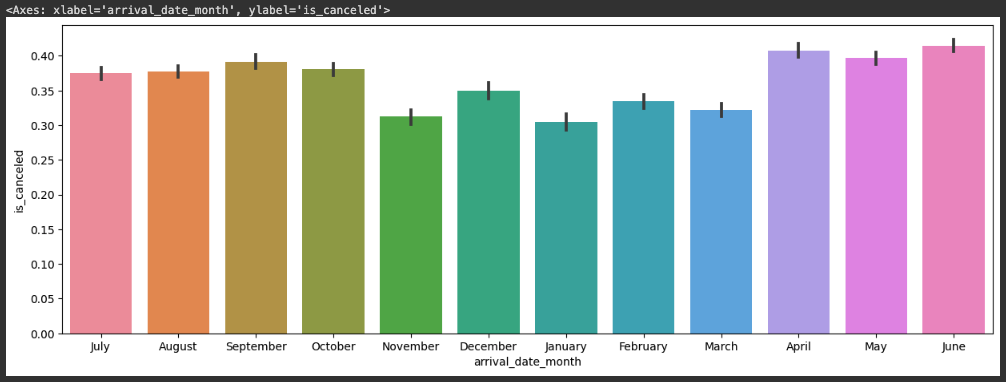
import calendar
print(calendar.month_name[1])
print(calendar.month_name[2])
print(calendar.month_name[3])
# 출력값 =>
# January
# February
# March
months=[]
for i in range(1,13):
months.append(calendar.month_name[i])
months
# 출력값 =>
# ['January',
# 'February',
# 'March',
# 'April',
# 'May',
# 'June',
# 'July',
# 'August',
# 'September',
# 'October',
# 'November',
# 'December']plt.figure(figsize=(15,5))
sns.barplot(x=hotel_df['arrival_date_month'],y=hotel_df['is_canceled'],order=months)
sns.barplot(x=hotel_df['is_repeated_guest'],y=hotel_df['is_canceled'])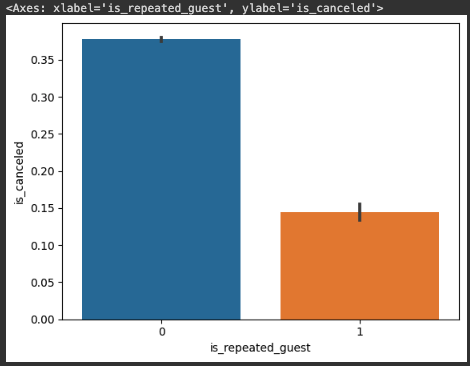
sns.barplot(x=hotel_df['deposit_type'], y=hotel_df['is_canceled'])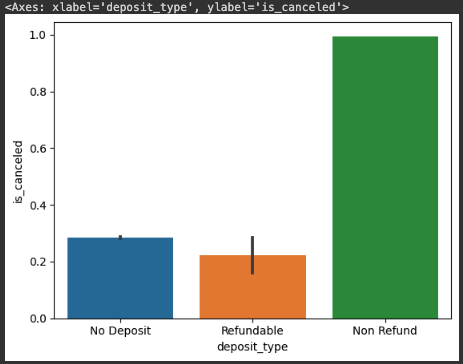
hotel_df['deposit_type'].value_counts()
# 출력값 =>
# No Deposit 104641
# Non Refund 14587
# Refundable 162# corr() : 열들 간의 상관관계를 계산하는 함수, 피어슨 상관계수
# -1 ~ 1까지의 범위를 가지며 0에 가까울수록 두 변수의 상관관계가 없거나 매우 약함
plt.figure(figsize=(15, 15))
sns.heatmap(hotel_df.corr(), cmap='coolwarm', vmax=1, vmin=-1, annot=True)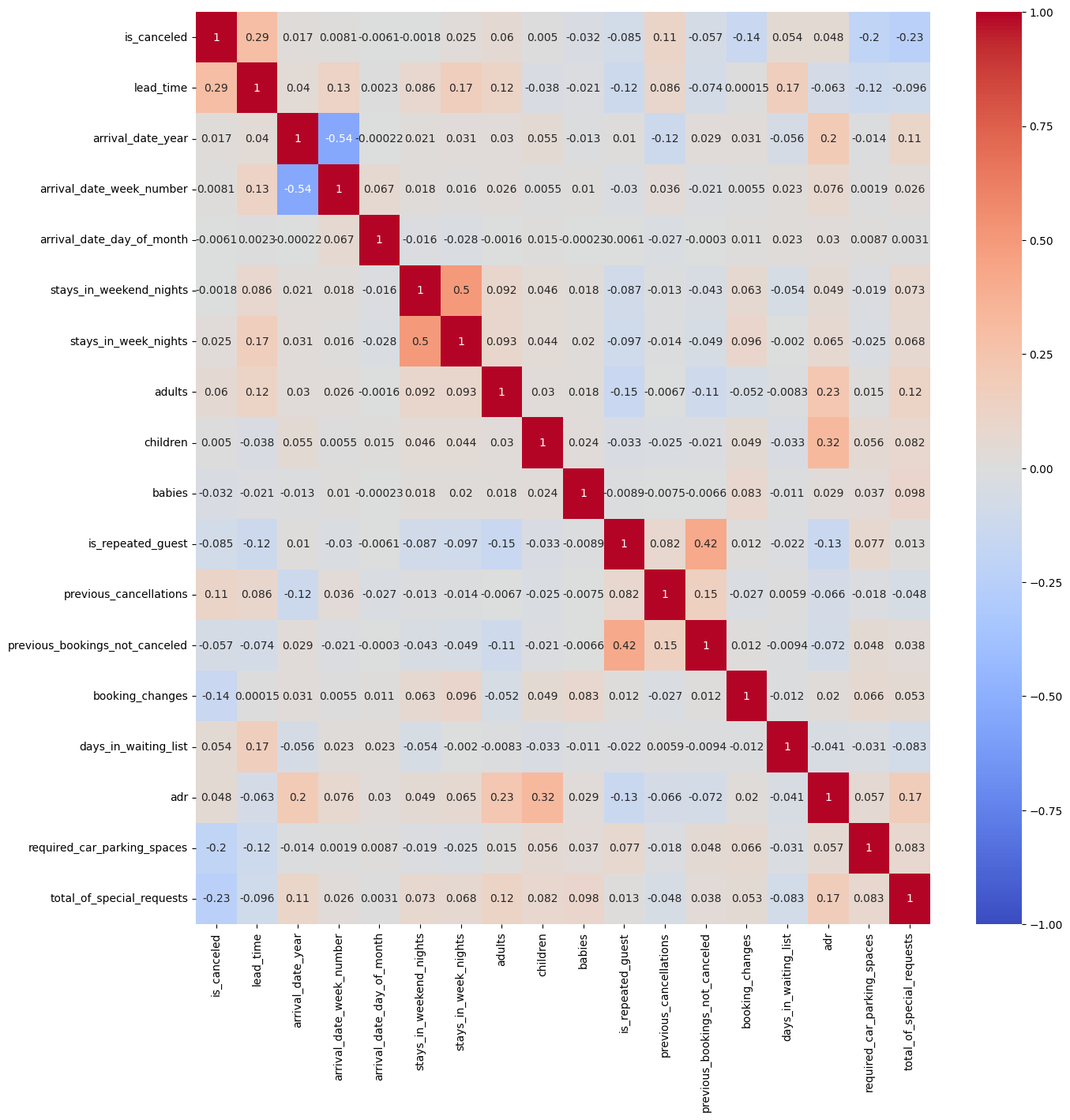
hotel_df = hotel_df.dropna()
hotel_df[hotel_df['adults'] == 0]
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
hotel_df[hotel_df['people'] == 0]
hotel_df = hotel_df[hotel_df['people'] != 0]
hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
hotel_df[hotel_df['total_nights'] == 0]
# season 파생변수 만들기
# arrival_date_month를 참고하여 생성
# 12, 1, 2 : winter
# 3, 4, 5 : spring
# 6, 7, 8 : summer
# 9, 10, 11 : fall
season_dic = {'spring':[3, 4, 5], 'summer':[6, 7, 8], 'fall':[9, 10, 11], 'winter':[12, 1, 2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar .month_name[j]] = i
new_season_dic
# 결과값 =>
# {'March': 'spring',
# 'April': 'spring',
# 'May': 'spring',
# 'June': 'summer',
# 'July': 'summer',
# 'August': 'summer',
# 'September': 'fall',
# 'October': 'fall',
# 'November': 'fall',
# 'December': 'winter',
# 'January': 'winter',
# 'February': 'winter'}
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)
hotel_df['cancel_rate'] = hotel_df['previous_cancellations'] / (hotel_df['previous_bookings_not_canceled'] + hotel_df['previous_cancellations'])
hotel_df[hotel_df['cancel_rate'].isna()] # 첫방문으로 인하여 NaN값이 출력됨.
hotel_df['cancel_rate'] = hotel_df['cancel_rate'].fillna(-1)
hotel_df['country'].dtype
# 결과값 => dtype('O')
hotel_df['people'].dtype
# 결과값 => dtype('float64')
obj_list = []
for i in hotel_df.columns:
if hotel_df[i].dtype == 'O':
obj_list.append(i)
obj_list
# 결과값 =>
# ['hotel',
# 'arrival_date_month',
# 'meal',
# 'country',
# 'distribution_channel',
# 'reserved_room_type',
# 'assigned_room_type',
# 'deposit_type',
# 'customer_type',
# 'season']
for i in obj_list:
print(i, hotel_df[i].unique())
# 결과값 =>
# hotel ['Resort Hotel' 'City Hotel']
# arrival_date_month ['July' 'August' 'September' 'October' 'November' 'December' 'January'
# 'February' 'March' 'April' 'May' 'June']
# meal ['BB' 'FB' 'HB' 'SC' 'Undefined']
# country ['PRT' 'GBR' 'USA' 'ESP' 'IRL' 'FRA' 'ROU' 'NOR' 'OMN' 'ARG' 'POL' 'DEU'
# 'BEL' 'CHE' 'CN' 'GRC' 'ITA' 'NLD' 'DNK' 'RUS' 'SWE' 'AUS' 'EST' 'CZE'
# 'BRA' 'FIN' 'MOZ' 'BWA' 'LUX' 'SVN' 'ALB' 'IND' 'CHN' 'MEX' 'MAR' 'UKR'
# 'SMR' 'LVA' 'PRI' 'SRB' 'CHL' 'AUT' 'BLR' 'LTU' 'TUR' 'ZAF' 'AGO' 'ISR'
# 'CYM' 'ZMB' 'CPV' 'ZWE' 'DZA' 'KOR' 'CRI' 'HUN' 'ARE' 'TUN' 'JAM' 'HRV'
# 'HKG' 'IRN' 'GEO' 'AND' 'GIB' 'URY' 'JEY' 'CAF' 'CYP' 'COL' 'GGY' 'KWT'
# 'NGA' 'MDV' 'VEN' 'SVK' 'FJI' 'KAZ' 'PAK' 'IDN' 'LBN' 'PHL' 'SEN' 'SYC'
# 'AZE' 'BHR' 'NZL' 'THA' 'DOM' 'MKD' 'MYS' 'ARM' 'JPN' 'LKA' 'CUB' 'CMR'
# 'BIH' 'MUS' 'COM' 'SUR' 'UGA' 'BGR' 'CIV' 'JOR' 'SYR' 'SGP' 'BDI' 'SAU'
# 'VNM' 'PLW' 'QAT' 'EGY' 'PER' 'MLT' 'MWI' 'ECU' 'MDG' 'ISL' 'UZB' 'NPL'
# 'BHS' 'MAC' 'TGO' 'TWN' 'DJI' 'STP' 'KNA' 'ETH' 'IRQ' 'HND' 'RWA' 'KHM'
# 'MCO' 'BGD' 'IMN' 'TJK' 'NIC' 'BEN' 'VGB' 'TZA' 'GAB' 'GHA' 'TMP' 'GLP'
# 'KEN' 'LIE' 'GNB' 'MNE' 'UMI' 'MYT' 'FRO' 'MMR' 'PAN' 'BFA' 'LBY' 'MLI'
# 'NAM' 'BOL' 'PRY' 'BRB' 'ABW' 'AIA' 'SLV' 'DMA' 'PYF' 'GUY' 'LCA' 'ATA'
# 'GTM' 'ASM' 'MRT' 'NCL' 'KIR' 'SDN' 'ATF' 'SLE' 'LAO']
# distribution_channel ['Direct' 'Corporate' 'TA/TO' 'Undefined' 'GDS']
# reserved_room_type ['C' 'A' 'D' 'E' 'G' 'F' 'H' 'L' 'B']
# assigned_room_type ['C' 'A' 'D' 'E' 'G' 'F' 'I' 'B' 'H' 'L' 'K']
# deposit_type ['No Deposit' 'Refundable' 'Non Refund']
# customer_type ['Transient' 'Contract' 'Transient-Party' 'Group']
# season ['summer' 'fall' 'winter' 'spring']
for i in obj_list:
print(i, hotel_df[i].nunique())
# 결과값 =>
# hotel 2
# arrival_date_month 12
# meal 5
# country 177
# distribution_channel 5
# reserved_room_type 9
# assigned_room_type 11
# deposit_type 3
# customer_type 4
# season 4
hotel_df.drop(['country', 'meal'], axis=1, inplace=True)
obj_list.remove('country')
obj_list.remove('meal')
hotel_df = pd.get_dummies(hotel_df, columns=obj_list)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis=1), hotel_df['is_canceled'], test_size=0.3, random_state=2023)
X_train.shape, y_train.shape
# 결과값 => ((83109, 71), (83109,))
X_test.shape, y_test.shape
# 결과값 => ((35619, 71), (35619,))
2. 앙상블(Ensemble) 모델
- 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법을 사용하는 모델
- 보팅(Voting)
- 서로 다른 알고리즘 model을 조합해서 사용
- 모델에 대해 투표로 결과를 도출
- 배깅(Begging)
- 같은 알고리즘 내에서 다른 sample 조합을 사용
- 샘플 중복 생성을 통해 결과를 도출
- 부스팅(Boosting)
- 약한 학습기들을 순차적으로 학습시켜 강력한 학습기를 만듦
- 이전 오차를 보완해가면서 가중치를 부여
- 성능이 매우 우수하지만, 잘못된 레이블이나 아웃라이어에 대해 필요이상으로 민감
- AdaBoost, Gradient Boosting, XGBoost, LightGBM
- 스태킹(stacking)
- 다양한 개별 모델들을 조합하여 새로운 모델을 생성
- 다양한 모델들을 학습시켜 예측 결과를 얻은 다음 다양한 모델들의 예측 결과를 입력으로 새로운 메타모델을 학습
3. 랜덤 포레스트(Random Forest)
- 머신러닝에서 많이 사용되는 앙상블 기법중 하나이며 결정 나무를 기반으로 함
- 학습을 통해 구성해 놓은 결정 나무로부터 분류 결과를 취합해서 결론을 얻는 방식
- 성능은 꽤 우수한 편이나 오버피팅 하는 경향이 있음
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
pred1 = rf.predict(X_test)
proba1 = rf.predict_proba(X_test)
# 첫번째 테스트 데이터에 대한 예측 결과
proba1[0]
# 결과값 => array([0.96, 0.04])
# 모든 테스트 데이터에 대한 호텔 예약을 취소할 확률만 출력
proba1[:, 1]
# 결과값 =>
#array([0.04 , 0.1 , 0.06 , ..., 0.62 , 0.02 ,
# 0.76565272])
3-1. 머신러닝, 딥러닝에서 모델의 성능을 평가하는데 사용하는 측정값
- Accuracy : 올바른 예측의 비율
- Precision : 모델에서 수행한 총 긍정 예측 수에 대한 참 긍정 예측의 비율
- Recall : 실제 긍정 사례의 총 수에 대한 참 긍정 예측의 비율
- F1 Score : 정밀도와 재현율의 조화 평균이며, 정밀도와 재현율 간의 균형을 맞추기 위한 단일 맽트릭으로 사용
- AUC-ROC Curve(Area Under the Receiver Operating Characteristic) : 참양성률과 가양성률 간의 균형을 측정
- ROC Curve : 이진 분류의 성능을 측정하는 도구
- AUC : ROC 커브와 직선 사이의 면적으로 의미, 범위는 0.5 ~ 1 이며 값이 클수록 예측의 정확도가 높음
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
accuracy_score(y_test, pred1)
# 결과값 => 0.859850080013476
confusion_matrix(y_test, pred1)
# 결과값 =>
#array([[20833, 1602],
# [ 3390, 9794]])
print(classification_report(y_test, pred1))
# 결과값 =>
# precision recall f1-score support
#
# 0 0.86 0.93 0.89 22435
# 1 0.86 0.74 0.80 13184
#
# accuracy 0.86 35619
# macro avg 0.86 0.84 0.84 35619
# weighted avg 0.86 0.86 0.86 35619
roc_auc_score(y_test, proba1[:, 1])
# 결과값 => 0.926356200139129
# 하이퍼 파라미터 수정(max_depth=30을 적용)
rf2 = RandomForestClassifier(max_depth=30, random_state=2023)
rf2.fit(X_train, y_train)
proba2 = rf2.predict_proba(X_test)
roc_auc_score(y_test, proba2[:, 1])
# 결과값 => 0.9282014901868613
# 하이퍼 파라미터 적용 전 - 하이퍼 파라미터 적용 후
0.9263605986333767 - 0.9282014901868613
# 결과값 => -0.0018408915534845471
roc_auc_score(y_test, proba2[:, 1])
# 결과값 => 0.9282014901868613
import matplotlib.pyplot as py
from sklearn.metrics._plot.roc_curve import roc_curve
fpr, tpr, thr = roc_curve(y_test, proba2[:, 1])
print(fpr, tpr, thr)
plt.plot(fpr, tpr, label='ROC Curve')
plt.plot([0, 1], [0, 1])
plt.show()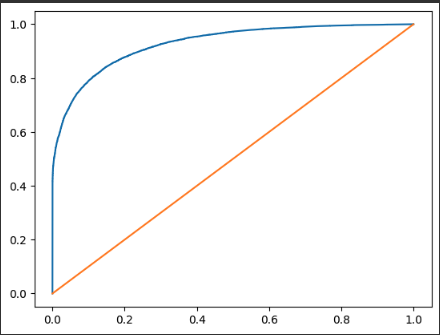
# 하이퍼 파라미터 수정(max_depth=50을 적용)
rf3 = RandomForestClassifier(max_depth=50, random_state=2023)
rf3.fit(X_train, y_train)
proba3 = rf3.predict_proba(X_test)
roc_auc_score(y_test, proba3[:, 1])
# 결과값 => 0.9266842801399297
# 하이퍼 파라미터 적용 전
0.9263605986333767
# 하이퍼 파라미터 적용 후 (max_depth=30)
0.9282014901868613
# 하이퍼 파라미터 적용 후 (max_depth=50)
0.9266842801399297
# 하이퍼 파라미터 수정(min_samples_split=5을 적용)
rf4 = RandomForestClassifier(min_samples_split=5, random_state=2023)
rf4.fit(X_train, y_train)
proba4 = rf4.predict_proba(X_test)
roc_auc_score(y_test, proba4[:, 1])
# 결과값 => 0.9267326196255201
# 하이퍼 파라미터 적용 전
0.9263605986333767
# 하이퍼 파라미터 적용 후(min_samples_split=5)
0.9267326196255201
# 하이퍼 파라미터 수정(min_samples_split=10을 적용)
rf5 = RandomForestClassifier(min_samples_split=10, random_state=2023)
rf5.fit(X_train, y_train)
proba5 = rf5.predict_proba(X_test)
roc_auc_score(y_test, proba5[:, 1])
# 결과값 => 0.9246455696039908
# 하이퍼 파라미터 적용 전
0.9263605986333767
# 하이퍼 파라미터 수정(max_depth=30)
0.9282014901868613
# 하이퍼 파라미터 수정(max_depth=50)
0.9266842801399297
# 하이퍼 파라미터 수정(min_samples_split=5)
0.9267326196255201
# 하이퍼 파라미터 수정(min_samples_split=10)
0.9246455696039908
3-2. 하이퍼 파라미터 최적의 값을 찾는 방법
- GridSearchCV : 원하는 모든 하이퍼 파라미터를 적용하여 최적의 값을 찾음
- RandomizedSearchCV : 원하는 하이퍼 파라미터를 지정하고 n_iter값을 설정하여해당 수 만큼 random하게 조합하여 최적의 값을 찾음
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
params = {
'max_depth': [None, 10, 30, 50],
'min_samples_split': [2, 3, 5, 7, 10]
}
rf6 = RandomForestClassifier(random_state=2023)
grid_df = GridSearchCV(rf6, params, cv=5, n_jobs= -1) # cv : 데이터 교차 검증, 만약 cv를 지정은 안하거나 none을 하면 자동으로 5가 잡힌다.
grid_df = GridSearchCV(rf6, params, cv=2, n_jobs= -1) # 그래서 cv는 2로 낮추고 진행
grid_df.fit(X_train, y_train)
# 가장 성능이 좋은 값일때 조건을 보여달라
grid_df.best_params_
# 출력값 => {'max_depth': 30, 'min_samples_split': 3}
rf7 = RandomForestClassifier(min_samples_split=3, random_state=2023)
rf7.fit(X_train, y_train)
proba7 = rf7.predict_proba(X_test)
roc_auc_score(y_test, proba7[:, 1])
# 출력값 => 0.9265883060773193
test = RandomForestClassifier(min_samples_split=3, max_depth=30, random_state=2023)
test.fit(X_train, y_train)
proba_t = test.predict_proba(X_test)
roc_auc_score(y_test, proba_t[:, 1])
# 출력값 => 0.9272801391858032
# 하이퍼 파라미터 적용 전
0.9263605986333767
# 하이퍼 파라미터 수정(max_depth=30)
0.9282014901868613
# 하이퍼 파라미터 수정(max_depth=50)
0.9266842801399297
# 하이퍼 파라미터 수정(min_samples_split=5)
0.9267326196255201
# 하이퍼 파라미터 수정(min_samples_split=10)
0.9246455696039908
# 하이퍼 파라미터 최적의 값(min_samples_split: 3)
0.9265883060773193
rf8 = RandomForestClassifier(max_depth=30, random_state=2023)
rf8.fit(X_train, y_train)
proba8 = rf8.predict_proba(X_test)
roc_auc_score(y_test, proba8[:, 1])
# 결과값 => 0.9282014901868613
params = {
'max_depth': [None, 10, 30, 50],
'min_samples_split': [2, 3, 5, 7, 10]
}
rf9 = RandomForestClassifier(random_state=2023)
rand_df = RandomizedSearchCV(rf9, params, n_iter=10, random_state=2023)
rand_df.fit(X_train, y_train)
rand_df.best_params_
# 결과값 => {'min_samples_split': 3, 'max_depth': 30}
rf10 = RandomForestClassifier(min_samples_split=3, max_depth=30, random_state=2023)
rf10.fit(X_train, y_train)
proba10 = rf10.predict_proba(X_test)
roc_auc_score(y_test, proba10[:, 1])
# 결과값 => 0.9272801391858032
3-3. 피처 중요도(Feature Importances)
- 결정 나무에서 노드를 분기할 때 해당 피처가 클래스를 나누는데 얼마나 영향을 미쳤는지 표기하는 척도
- 0에 가까우면 클래스를 구분하는데 해당 피처의 영향이 거의 없다는 것이며, 1에 가까우면 해당 피처가 클래스를 나누는데 영향을 많이 줬다는 의미
proba10 = rf10.predict_proba(X_test)
roc_auc_score(y_test, proba10[:, 1])
# 결과값 => 0.9272801391858032
rf10.feature_importances_
# 결과값 =>
# array([1.19597451e-01, 2.12169097e-02, 4.55426307e-02, 5.63770318e-02,
# 2.05726199e-02, 3.08173980e-02, 9.74067304e-03, 5.13141792e-03,
# 8.83072295e-04, 2.21041310e-03, 3.05376018e-02, 3.29227544e-03,
# 2.11176776e-02, 2.92937307e-03, 9.13089633e-02, 2.21722326e-02,
# 5.57994029e-02, 1.29838711e-02, 3.42503570e-02, 2.73943421e-02,
# 2.95963655e-02, 7.18714231e-03, 7.42131772e-03, 3.45395542e-03,
# 3.95743516e-03, 1.96145061e-03, 2.67790340e-03, 1.91960671e-03,
# 3.90714233e-03, 3.45845064e-03, 2.99613484e-03, 3.55977787e-03,
# 2.45146619e-03, 3.00503065e-03, 2.90079303e-03, 2.74405324e-03,
# 8.20976969e-03, 2.53655584e-04, 1.25147108e-02, 1.53508309e-07,
# 5.91625275e-03, 8.10463966e-04, 6.63826385e-04, 3.82096452e-03,
# 2.21152172e-03, 1.20292432e-03, 1.12562804e-03, 3.90090229e-04,
# 1.87251668e-05, 1.19564794e-02, 1.35465031e-03, 1.05907303e-03,
# 5.41937214e-03, 2.39169269e-03, 1.54667042e-03, 1.12283937e-03,
# 4.50264941e-04, 9.67760759e-05, 1.05844446e-04, 0.00000000e+00,
# 8.86886831e-02, 1.02807279e-01, 4.66372935e-04, 2.90869071e-03,
# 4.17574915e-04, 1.72845616e-02, 1.21627561e-02, 3.49951574e-03,
# 3.84454422e-03, 4.56373587e-03, 3.64019600e-03])feat_imp = pd.DataFrame({
'features': X_train.columns,
'importances': rf10.feature_importances_
})
feat_imp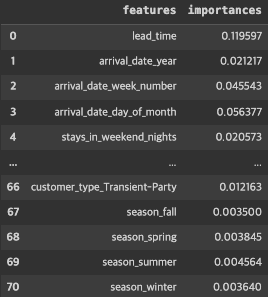
top10 = feat_imp.sort_values('importances', ascending=False).head(10)
top10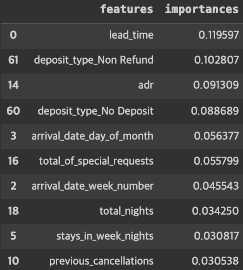
plt.figure(figsize=(5, 10))
sns.barplot(x='importances', y='features', data=top10)
'Study > 머신러닝과 딥러닝' 카테고리의 다른 글
| [머신러닝과 딥러닝] 11. 다양한 모델 적용 (0) | 2024.01.08 |
|---|---|
| [머신러닝과 딥러닝] 10. lightGBM (0) | 2024.01.05 |
| [머신러닝과 딥러닝] 8. 서포트 백터 머신 (0) | 2024.01.02 |
| [머신러닝과 딥러닝] 7. 로지스틱 회귀 (0) | 2024.01.02 |
| [머신러닝과 딥러닝] 6. 의사 결정 나무 (0) | 2023.12.29 |